强化学习的数学原理-notes
P1 Basic Concepts
State: The status of the agent with respect to the environment.
- grid-world example: the location of the agent ().
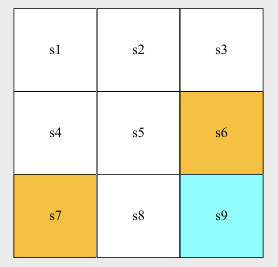
State space: the set of all states .
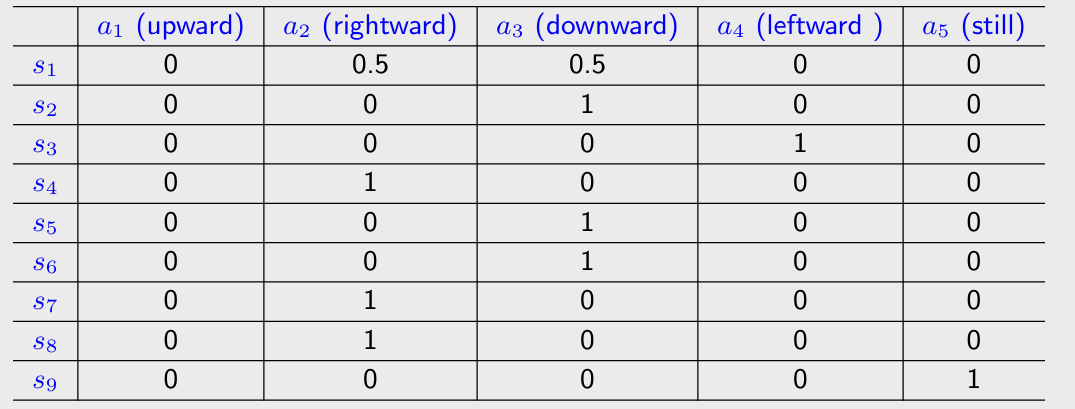
Action: For each state, there are lots of possible actions: .
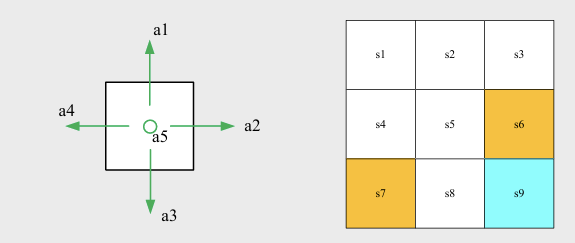
Action space of a state: the set of all possible actions of a state. .
State transition: When taking an action, the agent may move from one state to another. It defines the interaction with the environment.
- Tabular representation: could only represent deterministic cases.
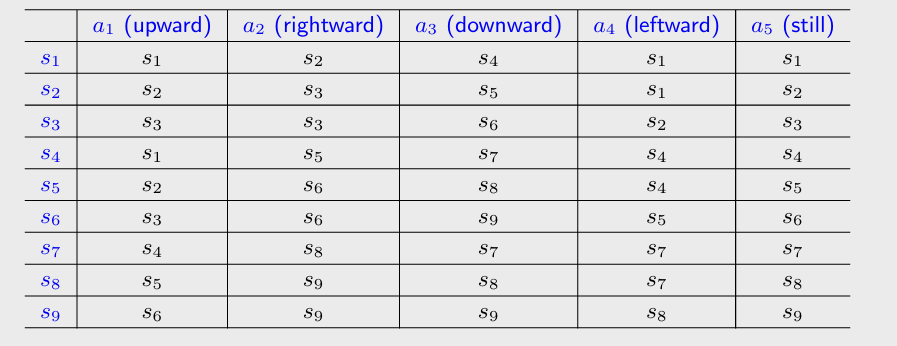
- State transition probability: use probability to describe state transition. This could be deterministic or stochastic.
Policy: tells the agent what actions to take at a state.
- Intuitive representation:
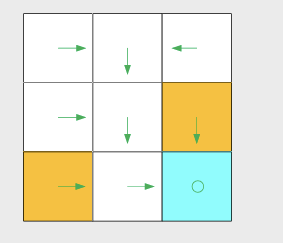
- Mathematical representation: using conditional probability
- Tabular representation: could be deterministic or stochastic cases.
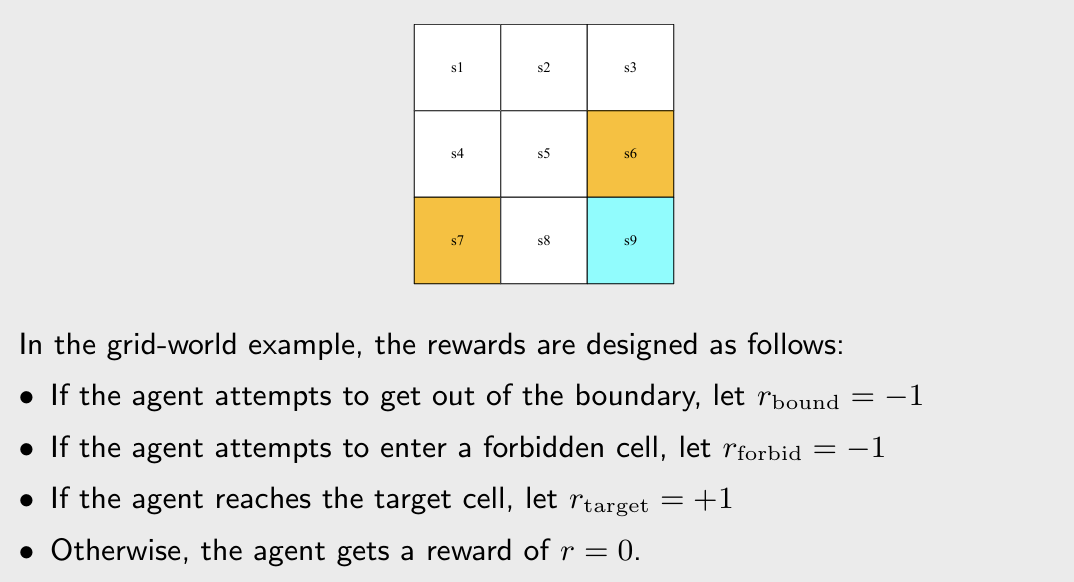
Reward: could be interpreted as a Human-machine interface. A real number we get after taking an action.
- A positive reward represents encouragement to take such actions.
- A negative reward represents punishment to take such actions.
- Tabular representation:

- Mathematical description: conditional probability
Trajectory: a state-action-reward chain:
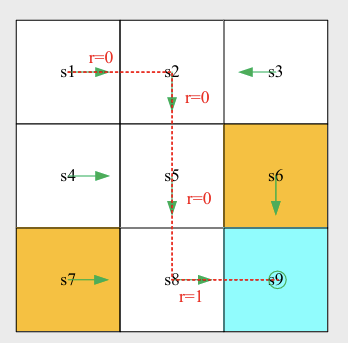
Return: the sum of all the rewards collected for specific trajectory
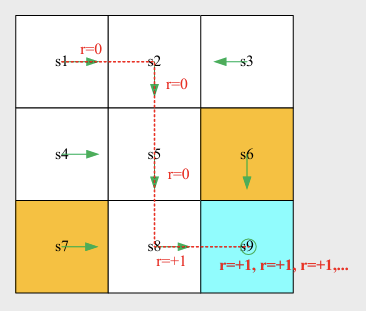
Discounted return: introduce a discount rate $\tau \in \left[0, 1 \right)$ to solve the infinite return problem.
- If is close to 0, the value of discounted return is dominated by the rewards obtained in the near future.
- If is close to 1, the value of discounted return is dominated by the rewards obtained in the far future.
Episode: the agent may stop at some terminal states. The resulting trajectory is called an episode (trial).
An Episode is usually assumed to be a finite trajectory. We treat episode as a continuing tasks which means that this task has no terminal state.
Markov decision process (MDP)
Sets:
- State: the set of states
- Action: the set of actions is associated for state
- Reward: the set of rewards
Probability distribution
- State transition probability: at state $s$ , taking action $a$, the probability to transit to state $s^\prime$ is $p(s^\prime | s, a)$
- Reward probability: at state $s$, taking action $a$, the probability to get reward $r$ is $p(r|s, a)$
- Policy: at state $s$, the probability to choose action a is $\pi(a|s)$
- Markov property: memoryless property
P2 bellman Equation
Motivation
The return reflects the efficacy of the policy: policy 1 is the best and the policy 2 is the worst.
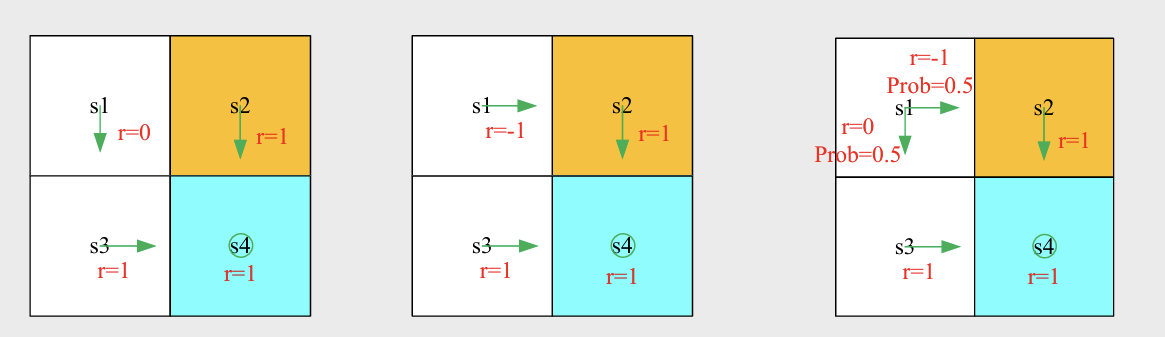
State Value
Consider the following single-step process:
This step is governed by the following probability distributions:
Consider the following multi-step trajectory:
The discounted return: , $\tau \in (0, 1)$ is discounted rate.
State value: the expectation of :
- It is a function of . It is a conditional expectation with the condition that the state starts from .
- It is based on the policy . For a different policy, the state value may be different.
- It represents the “value” of a state. If the state value is greater, the policy is better.
Bellman equation
Consider a random trajectory:
The return can be written as:
Then:
For the first term :
For the second term :
Therefore: