25 IJCAI Image-Enhanced Hybrid Encoding with Reinforced Constrastive Learning for Spatial Domain Identification in Spatial Transcriptomics
code link: wdyi701/IE-HERCL
paper link:
Concept
Frobenius 内积
两个矩阵进行逐元素的相乘, 并且将其累加。 可以用于衡量矩阵间的相似性。
optimal transport
用最小代价将一个分布转移为另一个分布
Earth Mover’s Distance (EMD) [1]
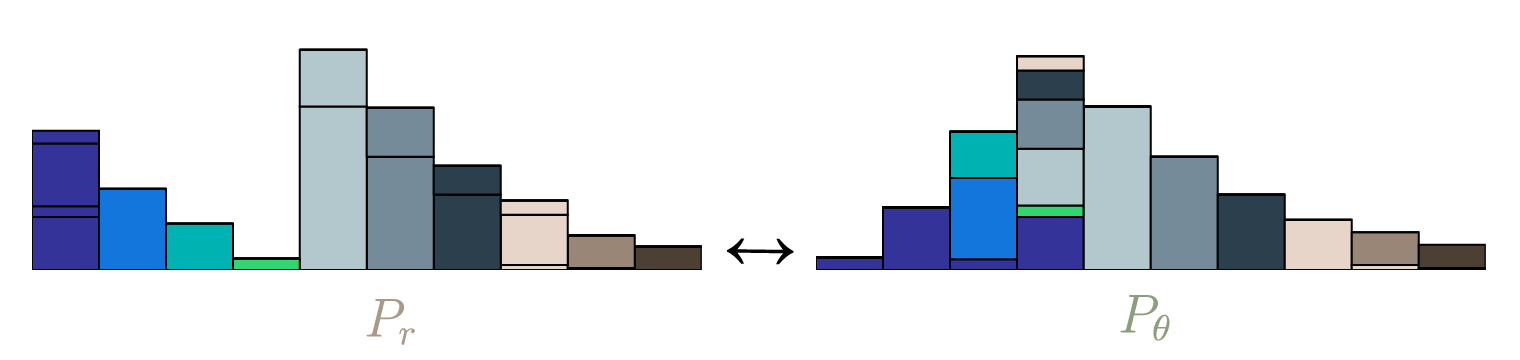
给定 $P_r$ 以最优传输转移为 $P_\theta$ , 当作推土任务最小化平均做功:
EMD的一般形式为:
其中 $\gamma(x,y)$ 为 moving plan 即从给定的 $x$ 移动到 $y$ 的质量, $||x - y||$ 为 $x$ 到 $y$ 位置的欧式距离, $\inf$ 为最大下界, $\Pi$ 为所有可能的 moving plan。
令 $\Gamma, \mathrm{D} \in \mathbb{R}^{l \times l}$ , 其中 $\Gamma = \gamma(x, y), D = ||x - y||$ 原式为:
最优 moving plan 为:
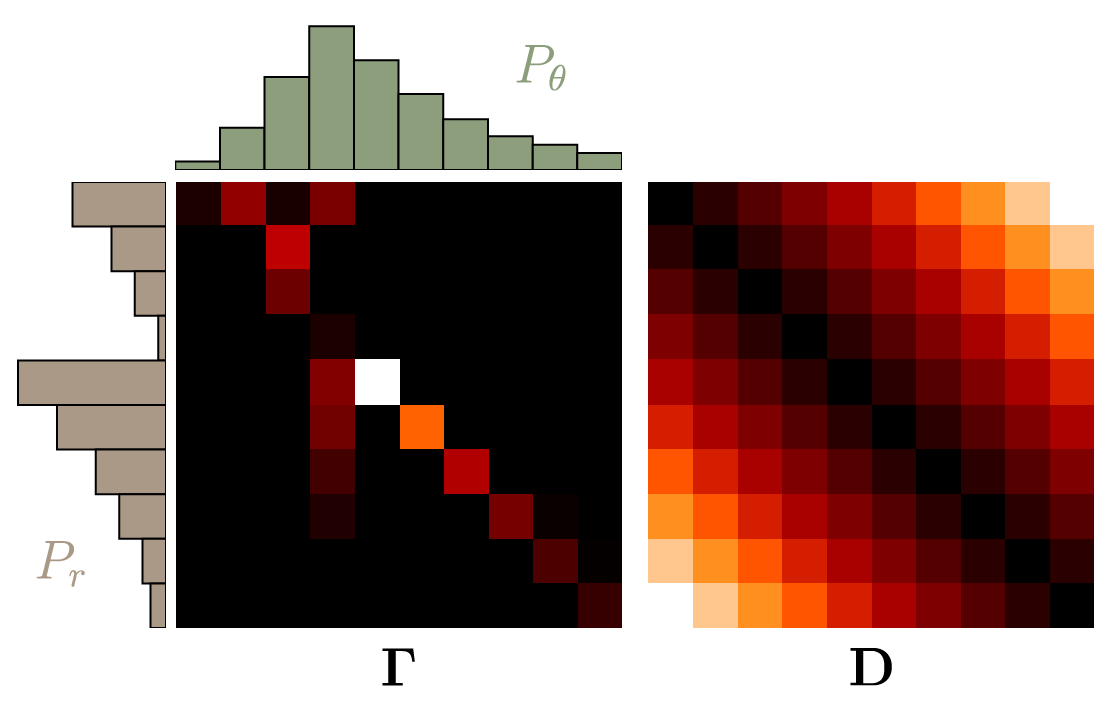
添加 entropy regularization 后将问题变为凸问题, 降低时间复杂度为 $O(n^2\log{n})$ 并且使解唯一。
矩阵 $P \in \mathbb{R}^{m \times n}$ 的熵为:
即矩阵越稀疏,混乱程度越低,熵越小。
作为正则项加入到原始 optimal transport 目标函数中:
其中 $\epsilon$ 为正则化强度, 该正则化鼓励高熵即利用多数小流量路径传输,惩罚稀疏利用少数大流量路径的传输。
Motivation
- 现有的方法难以完全整合空间坐标以及基因表达矩阵: 作者使用 GraphSAGE 聚合邻居信息生成具空间信息的细胞表示以建模空间依赖。
- 现有方法没有有效利用图像的信息:作者使用 dual-encoding 即使用 autoencoder 捕捉 非空间信息, 并使用 GraphSAGE 捕捉 空间信息以生成高效表示。
- 传统对比学习方法在多模态数据融合有 false-negative 样本问题:作者使用 high-order random walks 以建模样本间的转移概率以减少 false-negative 的影响。
- 作者利用 optimal transport 增强学习到表示的鲁棒性 。
Method
Multimodal Feature Representation Learning
采用 Autoencoder、 GraphSAGE encoder 和 cross-modal attention 提取表示并且增强语义一致性。
Feature Extraction for Gene Expression Data
采用 AE 最小化重构损失减少噪声、提取表示:
其中 $X_g \in \mathbb{R}^{N \times d}$ 是 gene expression, $Z_g \in \mathbb{R}^{N \times d^{\prime}}$ 是 latent space, $f_{\theta_d}^g$ and $f^g_{\theta_e}$ 是 encoder 和 decoder , $||\cdot||_F$ 是 Frobenius norm 。
Feature Extraction for Image Data
采用 pre-trained ResNet50 提取输入图像 $X_{img} \in \mathbb{R}^{N \times h \times w \times c}$ 为high-level feature $Z_{net} \in \mathbb{R} ^ {N \times d_{net}}$, 然后采用 autoencoder 学习 deeper latent representation $Z_{img} \in \mathbb{R}^{N \times d^{\prime}}$ 并最小化重构损失以提取 compact and representative features:
其中 $Z_{net, i}$ 是被 ResNet50提取的 $i-th$ 个image ,$f_{\theta_d}^{img}$ and $f^{img}_{\theta_e}$ 是 encoder 和 decoder 。
Local Structure Learning
采用 GraphSAGE encoder 通过邻接矩阵 $\mathrm{G} \in \mathbb{R}^{N \times N}$ 捕捉局部结构特征, 其中 $\mathrm{G}$ 是将 spot 间的空间距离小于一定 pixel distance 作为邻居构建的 spatial graph。 GraphSAGE 通过以下范式进行邻居表示的聚合:
其中 $Z_i^v$ 是更新了的节点表示, v 为节点类型(gene/ image),$\mathcal{N(i)}$ 为节点 $i$ 的邻居节点, $\text{Aggregate}\{\cdot \}$ 是聚合函数,$ \sigma(\cdot) $ 是激活函数, $W_e$ 是学习到的权重矩阵。
Cross-Modal Information Fusion
采用 intra-modal attention 进行模态内的自适应融合:
其中 $\alpha_{ae}$ 和 $\alpha_{gs}$ 是 AE 和 GraphSAGE encoding 的权重。
然后应用 cross-modal attention 整合不同模态的信息:
其中 $\beta_g$ 和 $\beta_{img}$ 是 learnable attention weights 。
Reconstruction of Gene Expression Data
采用 GraphSAGE Decoder 从表示 $Z$ 进行基因表示数据$\hat{X_g}$ 的重建:
其中 $W_d$ 是学习到的权重矩阵。
采用如下重建损失保证局部网络信息:
Overall Reconstruction Loss
Negative Sample Mitigation Strategy in Contrastive Learning
动态调节负样本影响以缓解假阴性对模型表征能力的影响。
Constructing the Transition Probability Matrix via Random Walks
将 node 视为sample, 并且以成对相似度作为 edge weights 首构建affinity graph,使用核函数构建邻接矩阵:
其中 $x_i$ and $x_j$是对应sample $i$ and $j$ 的 embedding, $\sigma$ 是控制相似度衰减比例的 smoothing parameter 。
随后为了探索 high-order neighborhood 关系, 在图上进行随机游走。随机游走概率转移矩阵 $M$ 为:
其中 $D$ 为节点度矩阵。
通过迭代 $\ref{high-order-transition}$, 计算 high-order 概率转移矩阵 $T$:
其中 $\alpha$ 为平衡 direct 和 high-order neighborhood 的平衡系数(默认为 0.5), t 为随机游走的步长。
Incorporating Transition Probilities into Contrastive Learning
将概率转移矩阵 $T$ 整合到对比学习框架中以减少错误负样本的影响:
其中 $\text{cos}(Z_i, Z_i^v)$ 是$Z_i$ and $Z_i^v$ 的 cosine similarity , $\tau$ 是温度参数(默认为 0.5),并且 $T_{ij}$ 是 从 sample $i$ 到 sample $j$ 的概率转移矩阵,以保证语义相似度远的对 loss 的影响较小。
Optimal Transport-Based Representation Optimization
采用 optimal transport-based self-optimization strategy 进行clustering align 。
Construction of Clustering and Auxiliary Distribution
定义量化每个样本属于不同类的 clustering distribution Q 为:
其中 $q_{i, u}$ 为 sample $i$ 属于 $\mu_u-th$ cluster 的概率, $z_i$ 是 sample $i$ 的 embedding, $\mu_k$ 是使用伪标签计算的聚类中心, $k$ 是聚类类别数量。
定义辅助分布 $P$ 用于增强高置信样本的分布:
Optimal Transport Objective
将其视为一个 optimal transport task, 目标函数是最小化 Q 到 P 的传输质量消耗, 并且通过 entropy regularization 保证平滑:
其中 $C$ 是 $Q$ 和 $P$ 中的点以欧氏距离为代价的代价矩阵, $\gamma_{i,j}$ 代表从 $Q$ 的 $i-th$ 元素到 $P$ 的 $j-th$ 元素的传输计划, $\epsilon$ 代表 entropy regularization 的强度。
为有效的评估分布间的一致性, 采用 Sinkhorn divergence [4]:
其中 $\ref{ot}$ 的优化直到达到预定义的最大迭代次数。 Sinkhorn divergence 提供了对于 EMD 可微分且可高效计算的近似替代方案 5。
$\ref{s_div}$ 的代码实现为:
1 | from ot.bregman import empirical_sinkhorn_divergence |
Overall Optimization Objective
总的损失函数为:
其中 $\lambda_1, \lambda_2 \ \text{and} \ \lambda_3$ 是不同损失的平衡项。
- 1.Wasserstein GAN 和 Kantorovich-Rubinstein 对偶性 - Vincent Herrmann --- Wasserstein GAN and the Kantorovich-Rubinstein Duality - Vincent Herrmann ↩
- 2.最优传输笔记(五):熵正则 - 知乎 ↩
- 3.最优运输(Optimal Transfort):从理论到填补的应用 - 舞动的心 - 博客园 ↩
- 4.Learning Generative Models with Sinkhorn Divergences ↩
- 5.Missing Data Imputation using Optimal Transport ↩